表データの代表的な形式の1つであるCSVファイル(エクセルなどで開けるカンマ区切りのデータ)をPythonで扱う方法について解説します。
目次
CSVファイルを開いたり閉じたりする場合もテキストファイルと同様open関数とcloseメソッドを使います。その際with文を使えばコードブロックの終了時にファイルを自動的に閉じてくれます。
with open("/Users/User/Desktop/python_lessons/lesson.csv",encoding="utf-8") as f:
ここに処理を書く
テキストファイルの読み込みではf変数に代入したファイルの中身を文字列型に変換したり、行ごとに分割してリストに格納する方法を学びました。
CSVファイルはカンマ区切りのテキストファイルなので、テキストファイルとして読み込んでカンマで分割処理をすることもできますが、PythonにはCSVやTSVといった任意の文字列で区切られたテキストファイルをより簡単に扱うためのCSVモジュールが標準ライブラリに用意されています。
リストとして読み込む
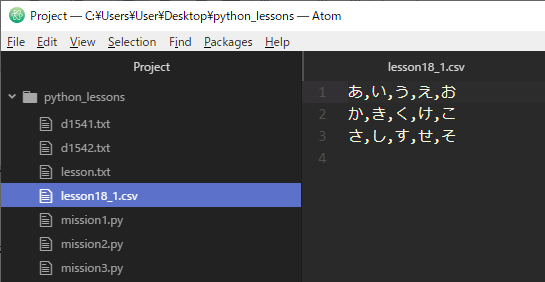
実際にCSVファイルを作成してPythonで読み込んでみましょう。例として『Python_lessons』フォルダの中に『lesson18_1.csv』という名前で次の内容を記述したCSVファイルを用意しました。文字コードはutf-8です。
このファイルをPythonプログラムの中で呼び出して開き、カンマ区切りの値を要素とした行ごとのリストとして表示するにはcsv.reader関数とfor文を使って次のように記述します。
import csv # csvモジュールをインポート
with open("/Users/User/Desktop/python_lessons/lesson18_1.csv",newline="",encoding="utf-8") as f: # csvファイルの読み込み
reader = csv.reader(f) # リスト型に変換してreader変数に代入
for row in reader:
print(row)
open関数の第2引数として指定しているnewline=””は改行コードが\r\nである環境(Windows)では指定しておくよう公式ドキュメントで推奨されています。(これがないと余分な\rが追加されてしまうことがあります。)
実行結果は次のとおりです。
['あ', 'い', 'う', 'え', 'お'] ['か', 'き', 'く', 'け', 'こ'] ['さ', 'し', 'す', 'せ', 'そ']
カンマ区切りの値を要素とした行ごとのリストとして表示できました。
これらを2次元リストとして取得したい場合はリスト内包表記を使って次のように記述するのが簡潔です。
import csv
with open("/Users/User/Desktop/python_lessons/lesson18_1.csv",newline="",encoding="utf-8") as f:
reader = csv.reader(f)
list = [row for row in reader] # リスト内包表記で記述
print(list)
実行結果は次のとおりです。
[['あ', 'い', 'う', 'え', 'お'], ['か', 'き', 'く', 'け', 'こ'], ['さ', 'し', ' す', 'せ', 'そ']]
各行のデータを要素とする2次元リストとして取得することができました。
辞書として読み込む
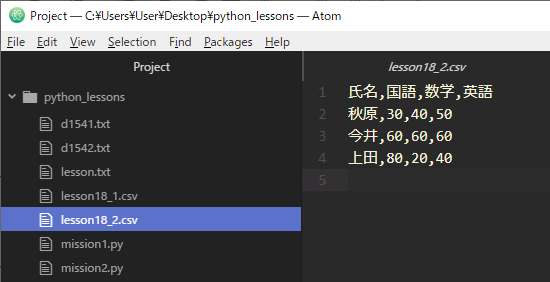
今度は先ほどのファイルでは例としてわかりにくいため、『lesson18_2.csv』という名前で次の内容を記述したCSVファイルを用意しました。文字コードはutf-8です。
CSVファイルを辞書として読み込みたい場合にはcsv.DictReaderとfor文のリスト内包表記を使って次のように記述します。
pprintモジュールを合わせて使うとデータを整然化して出力することができるため見やすくなります。
import csv
import pprint # pprintモジュールをインポート
with open("/Users/User/Desktop/python_lessons/lesson18_2.csv", newline="", encoding="utf-8") as f:
dict = csv.DictReader(f) # 辞書型として読み込み
list = [row for row in dict] # キーと値を1セット(タプル)にしたリストに変換
pprint.pprint(list) # pprintで整然化して出力
実行結果は次のとおりです。
[OrderedDict([('氏名', '秋原'), ('国語', '30'), ('数学', '40'), ('英語', '50')]),
OrderedDict([('氏名', '今井'), ('国語', '60'), ('数学', '60'), ('英語', '60')]),
OrderedDict([('氏名', '上田'), ('国語', '80'), ('数学', '20'), ('英語', '40')])]
csv.DictReaderのデフォルトでは1行目の値がフィールド名として扱われ、辞書のキーとなります。辞書がリストの中に格納される形となっていますね。
CSVファイルの書き込み
CSVファイルに書き込みを行うにはcsv.writer関数を使ってファイルの中身を読み込みます。ファイルは書き込みモードで開きましょう。
import csv
with open("/Users/User/Desktop/python_lessons/lesson18_3.csv", mode="w",newline="", encoding="utf-8") as f: # ファイルを開く
writer = csv.writer(f) # 書き込み用として読み込み
書き込みモード”w”ではテキストファイルの時と同様、指定したパスのファイルが存在していれば上書き保存され、存在しない場合は新規ファイルを作成してくれます。
リストの書き込み
では実際にcsvファイルを作成してリストを書き込んでみましょう。1行ずつリストとして書き込むにはwriterowメソッドの引数にリストを記述します。
import csv
with open("/Users/User/Desktop/python_lessons/lesson18_3.csv", mode="w",newline="", encoding="utf-8") as f:
writer = csv.writer(f) # 書き込み用として読み込み
writer.writerow([0, 1, 2]) # リストを書き込み
writer.writerow(["あ","い","う"]) # リストを書き込み
コードを実行し、作られたファイルの中身をAtomで確認してみましょう。
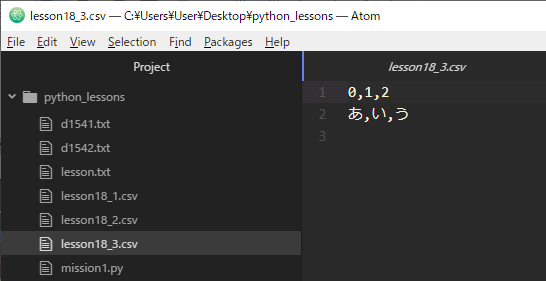
ちゃんと『lesson18_3.csv』という名前でデータがカンマで区切られたCSVファイルが作成されていますね。
次は2次元リストを書き込んでみましょう。writerowsメソッドを使います。
import csv
list = [["あ","い","う"], ["か","き","く"], ["さ","し","す"]]
with open("/Users/User/Desktop/python_lessons/lesson18_3.csv", mode="w",newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(list) # 2次元リストを書き込み
先ほどと同じファイル名を指定したので上書きされているはずです。Atomで確認してみましょう。
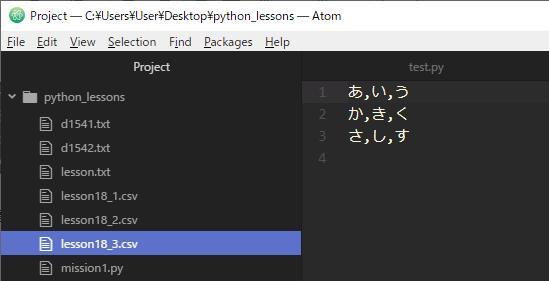
2次元リストの中の各リストが各行になって書き込まれているのがわかります。
上書きではなく既存のファイルに追記したい場合は追記モード”a”でファイルを開きます。書き込み自体は先ほどと同じようにwriterowメソッドやwriterowsメソッドを使います。
試しに先ほどのファイルに追記してみましょう。
import csv
with open("/Users/User/Desktop/python_lessons/lesson18_3.csv", mode="a",newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["た","ち","つ"]) # リストを追記
Atomでファイルを確認します。
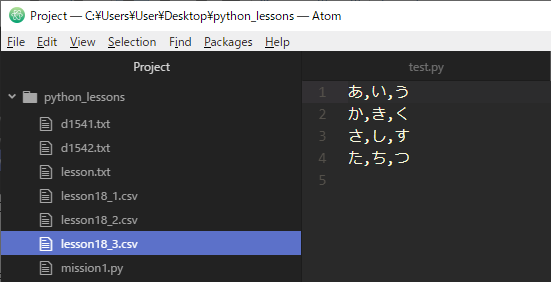
元々のファイルの中身を残したまま、新たに「た,ち,つ」という行を追記することができました。
辞書の書き込み
次はPythonで作成した辞書をCSVファイルに書き込む方法について見ていきましょう。ファイルを書き込みモードで開き、csv.DictWriterで辞書を書き込むための構造に変換します。
import csv
d1 = {"キー1": "秋原", "キー2": 30, "キー3": 40}
d2 = {"キー1": "今井", "キー3": 60}
with open("/Users/User/Desktop/python_lessons/lesson18_4.csv", mode="w",newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, ["キー1", "キー2", "キー3"]) # 書き込み用の構造に変換、キーを指定
writer.writeheader() # ヘッダー(見出し行)を書き込み
writer.writerow(d1) # 辞書を書き込み
writer.writerow(d2) # 辞書を書き込み
csv.DictWriterの第一引数に辞書を書き込むCSVファイルを、第二引数に書き込む辞書のキーをリスト形式で指定します。
ここで指定したキーはwriteheaderメソッドでヘッダー(見出し行)として書き込みます。
辞書の書き込みにはリストの時と同様writerowメソッドを使います。では実際にコードを実行し、作られたファイルをAtomで確認してみましょう。
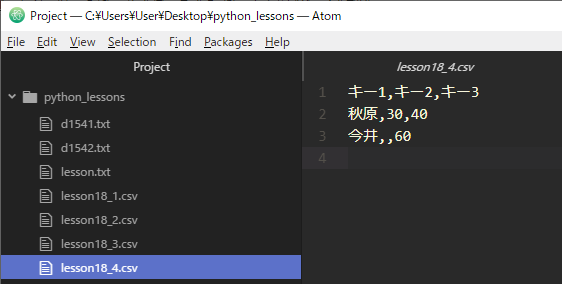
『lesson18_4.csv』という名前でCSVファイルが作成され、Pythonで作成した辞書が書き込まれているのがわかります。
今井くんの辞書にはキー2とそれに対応する値が格納されていないため、その要素がスキップされて空になっているのがわかります。
writerowsメソッドを使えば複数の辞書をまとめて書き込むこともできます。
import csv
d1 = {"キー1": "秋原", "キー2": 30, "キー3": 40}
d2 = {"キー1": "今井", "キー3": 60}
with open("/Users/User/Desktop/python_lessons/lesson18_4.csv", mode="w",newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, ["キー1", "キー2", "キー3"])
writer.writeheader()
writer.writerows([d1,d2]) # 辞書d1とd2をまとめて書き込み
このようにwriterowsメソッドを使って複数の辞書をまとめて書き込む場合には、各辞書を要素としたリストとして引数に指定します。
なおこの記事では扱いませんが、サードパーティライブラリのpandasを使うとCSVで保存するような表形式のデータ、特に数値の列や文字列の列が混在しているようなデータをより効率的に処理できます。
Pythonは標準ライブラリ以外にもこういった便利なライブラリがたくさんあるので、業務で使う場合は用途ごとにどんなライブラリがあるのがざっと調べておくと捗ります。