プログラムではファイル内に記載されたデータや標準入力のほか、外部からファイルを読み込んで処理したり、処理した内容を外部のファイルに書き込んだりすることもできます。この記事ではPythonでテキストファイルを扱う方法について解説します。
目次
ファイルを開く・閉じる
テキストファイルの内容を読み込むにしろ書き込むにしろ、まずはPythonプログラムの中でそのファイルを開く必要があります。
Pythonでは組み込み関数の1つであるopen関数でファイルを開き、closeメソッドでファイルを閉じることができます。
例えばテキストファイルを開き、何らかの処理をして閉じるコードは次のように記述します。
f = open("ファイルのパス")
ここに処理を書く
f.close()
処理の後ファイルを閉じることを忘れてしまうとPCのリソースを無駄に消費してしまったり、正しく処理を終わらせることができなかったりしますが、with文を使えばコードブロックの終了時に自動的に開いたファイルを閉じてくれます。
with文を使った記述は次のようになります。
with open("ファイルのパス") as f:
ここに処理を書く
ファイルの読み込み
文字列型として読み込む
では実際にテキストファイルを作成してPythonで読み込んでみましょう。
例として最初に作った『Python_lessons』フォルダの中に『lesson.txt』という名前で「あいうえお」と書いたテキストファイルを用意しました。文字コードはutf-8です。
このファイルをPythonプログラムの中で呼び出して開き、中の文字列を表示して閉じるには次のように記述します。
with open("/Users/User/Desktop/python_lessons/lesson.txt",encoding="utf-8") as f:
s = f.read()
print(s)
1~2行目でwith文の中でopen関数を使ってテキストファイルをパスで指定して呼び出し、f変数に代入しています。
WindowsではデフォルトだとCP932という文字コードで入出力しようとしてエラーになってしまうため、最後にencoding=”utf-8″ と記述しています。
この辺の話は文字コードやデータ型などややこしいのですが、今はあまりかっちり理解する必要はないので決まり文句として覚えておいてください。
テキストファイルから読み込んだ内容はio.TextIOWrapperという型で読み込まれるため、3行目でreadメソッドを使って文字列型に変換してs変数に代入しています。
ではコマンドプロンプトからこのPythonプログラムを実行してみましょう。
実行結果は次のようになります。
あいうえお
ちゃんとテキストファイルの中身が表示できました。
複数行のデータを読み込む
readメソッドは読み込んだファイルの中身を文字列型に変換してくれますが、ファイルの中身全体を1つの文字列として取得してしまうため複数行のデータを扱うことはできません。
ファイルの中身を1行ずつ文字列として取得して処理をしたい場合はfor文によるループ処理を使います。
with open("ファイルのパス") as f:
for カウンタ変数 in f:
ここに処理を書く
実際に試してみましょう。
まずは先ほどのテキストファイルに次のような複数行データを記述します。
あいうえお かきくけこ さしすせそ
このデータをPythonプログラムで読み込んで、各行に文字列を書き加えて出力してみましょう。
with open("/Users/User/Desktop/python_lessons/lesson.txt",encoding="utf-8") as f:
for s in f:
print(s.rstrip('\n') + " は" + s[0] + "行です")
for文でテキストファイルの中身を1行ずつ取得する場合、各行末尾の改行コード(\n)を含めて取得してしまうので、rstripメソッドを使って改行コードを削除してから他の文字列と連結して出力しています。
実行結果は次のようになります。
あいうえお はあ行です かきくけこ はか行です さしすせそ はさ行です
各行ごとに文字列を書き加えて出力することができました。
ファイルをリストとして読み込む
テキストファイルの中身が単文だったり、簡単な処理をするだけであれば上記の方法で事足りますが、複数行のデータである程度複雑な処理をしたい場合はリストとして取得すると便利です。
ファイルを行ごとに分割したリストとして取得するには次のように記述します。
with open("/Users/User/Desktop/python_lessons/lesson.txt",encoding="utf-8") as f:
l = [s.strip() for s in f.readlines()]
print(l)
リスト内包表記を使って、for文によるループ処理でファイルの各行をreadlinesメソッドで文字列に変換してs変数に代入、その後s変数の中身をstripメソッドを使って空白文字(改行コード)を削除してリストとして取得しています。
実行結果は次のようになります。
['あいうえお', 'かきくけこ', 'さしすせそ']
ちゃんとファイルの中身が行ごとに分割されてリストになっているのがわかります。
記法やメソッドがたくさんでてきてわけがわからないかもしれませんが、最初はこれらを事細かに全て覚える必要はありません。
テキストファイルの中身をPythonで扱うには型を変換する必要があるということと、複数のデータを扱う場合には書き方が違うということだけ把握しておきましょう。
よく使う記法やメソッドは使っているうちに覚えますし、忘れてしまったらググればいいのです。
ファイルの書き込み
文字列を書き込む
次はPythonでテキストファイルに書き込む方法についてみていきましょう。
ファイルに書き込みを行うにはファイルを書き込み用として開く必要があります。次のように記述します。
with open("ファイルのパス", mode="w") as fw:
fw.write("書き込みたい文字列")
open関数の第1引数にはファイルパスを記述しますが、第2引数でモードを指定することができます。
実はモードは読み込みの時にも指定しているのですが、引数modeのデフォルト値は “r” となっており、何も記述しなければ読み込み用としてファイルを開きます。
書き込み用としてファイルを開きたい場合はmodeの値を “w” にします。
ファイルを書き込みモードで開くと指定したパスのファイルが存在していれば上書き保存され、存在しない場合は新規ファイルを作成してくれます。
では実際に書き込みモードで文字列を書き込んだファイルを新規作成し、確認のためにそのファイルを読み込んで文字列として表示してみましょう。
with open("/Users/User/Desktop/python_lessons/write.txt", mode="w") as f:
f.write("私は魚")
with open("/Users/User/Desktop/python_lessons/write.txt") as f:
print(f.read())
with文を使って書き込みモードでファイルを開き、write.txt というファイル名を指定しています。
この名前のファイルは存在しないのでファイルが新規に作成され、3行目のwriteメソッドによって文字列を書き込んでいます。
4、5行目は先ほど学習したテキストファイルを読み込んで表示するコードです。
では実行結果をみてみましょう。
私は魚
Pythonで記述した内容が表示されました。
ちゃんとファイルとして作成されているかどうかAtomでも確認してみましょう。
文字コードについて
次の画像は先ほどのプログラムで作成したwrite.txt という名前のテキストファイルをAtomで開いたものです。
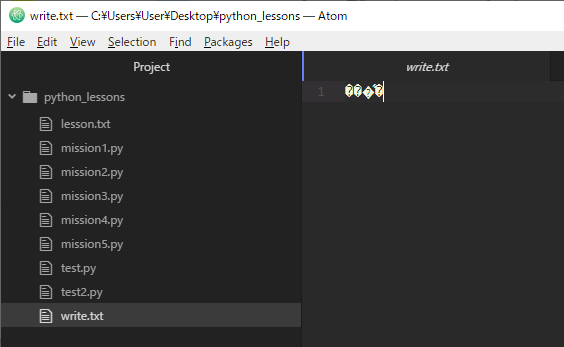
ファイルは作成できていますが中身が文字化けしてしまっています。
これはファイルの中身とエディタ側で文字コードが異なっており文字列が正常に変換できていないためです。
試しにAtomの文字コードをShift-JISに変換してみましょう。
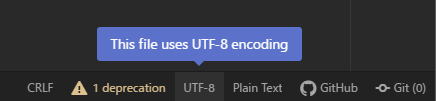
Atomの右下の『UTF-8』と書かれている部分(設定によって現在の文字コードは異なる可能性があります)をクリック。
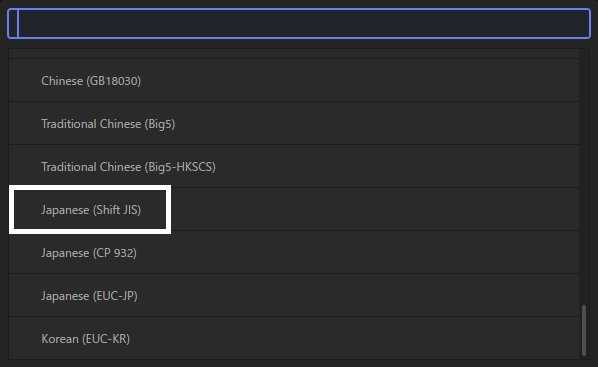
『Japanese (Shift-JIS)』を選択します。
先ほど書き込んだ通りの文章が表示されました。
このように文字コードが異なっていると読み込みや書き込み(入出力)の際に変換できず困ることがあります。そのため文字コードはなるべく統一しておきたいところです。
Pythonでのファイル書き込み時に文字コードを指定するには読み込み時と同様、第3引数で文字コードを指定します。
では先ほどのテキストファイルの文字コードをutf-8にして上書きしてみましょう。この場合は読み込む際も文字コードをutf-8に指定する必要があります。
with open("/Users/User/Desktop/python_lessons/write.txt", mode="w", encoding="utf-8") as f:
f.write("私は魚")
with open("/Users/User/Desktop/python_lessons/write.txt", encoding="utf-8") as f:
print(f.read())
これでwrite.txt ファイルの中身が上書きされました。エディタの文字コードをShift-JISにしたまま表示すると文字化けしてしまうのでUTF-8に戻しておきましょう。
ちなみになぜ変換が必要なUTF-8で学習を進めているかというと、WindowsはShift-JISを拡張したCP932という文字コードを採用していますが、Pythonを動作させる主要な環境はサーバーであり、サーバー環境として主流となっているLinuxやUNIXではUTF-8が採用されているためです。
リストを書き込み
話が文字コードの方に逸れてしまいましたがPythonでのテキストファイルへの書き込み方法の学習に戻りましょう。
次はリストを書き込む方法です。
l = ["つりざお", "はちまき", "くわ"]
with open("/Users/User/Desktop/python_lessons/write.txt", mode="w", encoding="utf-8") as f:
f.writelines(l)
リストをそのまま書き込むにはwritelinesメソッドを使います。作成したテキストファイルの中身は次のとおりです。
つりざおはちまきくわ
このようにwritelinesメソッドでは改行コードが挿入されず、リストの要素がそのまま連結されて書き込まれます。
これではファイルでリストを管理したい場合に不便です。要素ごとに改行コードで区切って書き込むには次のようにjoinメソッドでリストを改行込みの文字列に変換してwriteメソッドで書き込みます。
l = ["つりざお", "はちまき", "くわ"]
with open("/Users/User/Desktop/python_lessons/write.txt", mode="w", encoding="utf-8") as f:
f.write("\n".join(l))
作成したテキストファイルの中身は次のようになります。
つりざお はちまき くわ
これならテキストファイルの内容を先述の方法でリストとして再び読み込むことも可能です。
ちなみにwritelinesメソッドの引数に指定できるのは文字列を要素とするリストだけです。数値など他の型を要素とするリストを書き込みたい場合は、一度文字列のリストに変換する必要があります。
新規作成専用でファイルを開く
書き込みモードでは存在しないファイル名を指定することで新しいファイルを作成することができましたが、この方法でファイルを作成していると誤って既に存在するファイル名を指定してしまった場合、そのファイルの内容が上書きされて消えてしまいます。
こういった事故を防ぐためにファイルを新規作成する際は新規作成専用モードを使いましょう。
with open("/Users/User/Desktop/python_lessons/new_file.txt", mode="x") as f:
pass
ファイルを新規作成専用で開くには第2引数modeの値に”x”を指定します。このモードではファイルが存在しない場合のみファイルを作成し、既にその名前のファイルが存在する場合にはFileExistsErrorとなります。
with文の中に記述しているpassは「何も処理をしない」という命令文です。文法上withブロックの中身を空にすることはできませんが、こう記述しておくことで何も処理をせず、新規ファイルの作成のみを行うことができます。
では、試しに上記のコードを実行してみましょう。
1度目は実行結果としては何も表示されませんが、new_file.txtという新しいファイルが作成されています。
もう一度このコードを実行するとどうなるでしょうか。
実行結果は次のとおりです。
File "test.py", line 1, in <module>
with open("/Users/User/Desktop/python_lessons/new_file.txt", mode="x") as f:
FileExistsError: [Errno 17] File exists: '/Users/User/Desktop/python_lessons/new_file.txt'
FileExistsErrorが返されました。このように新規作成モードを使えば誤って既存のファイルを上書きしてしまう心配なくファイルを作成することができます。