OpenAIの画像生成AI DALL·E3 がついにChatGPTから使えるようになりました。2023年10月現在、有料版(ChatGPT PlusおよびEnterprise)のみのベータ機能となっています。この記事ではこのDALL·E3の使い方とDALL·E3でできることについてまとめます。
目次
DALL·E3とは
DALL·E3は、OpenAIが開発したいわゆる画像生成AIです。同じくOpenAIによって開発されたGPT-3を基盤とする画像生成モデルで、テキストの説明から画像を生成することができます。
前のバージョン(DALL·E2)よりも高度な生成能力や多様性を持っており、さまざまな種類の画像をより詳細に生成することができるようになりました。
簡単に言えば、ChatGPTのように日本語などの自然な文章を入力するだけで、それに関連する画像を生成してくれる画像生成AIです。
今のところ他の画像生成AIは単語区切りのプロンプトや、各パラメータでどのような画像を生成するか指示を出すことができましたが、自然な文章をそのまま投げるだけでいいのがDALL·E3(というかDALL·Eシリーズ)の特徴です。
ChatGPTでのDALL·E3の使い方
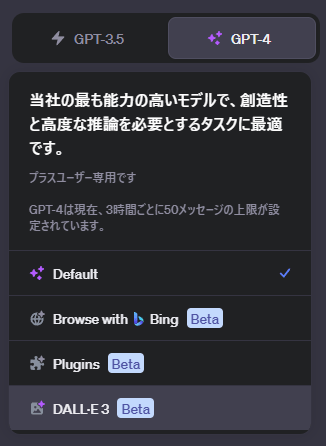
使い方は非常にシンプルで、ChatGPTにログインして、「新しいチャット」の「GPT-4」モデルから「DALL·E3」を選択するだけ。
あとは通常のChatGPTを使う時と同じように文章で指示を出すだけです。
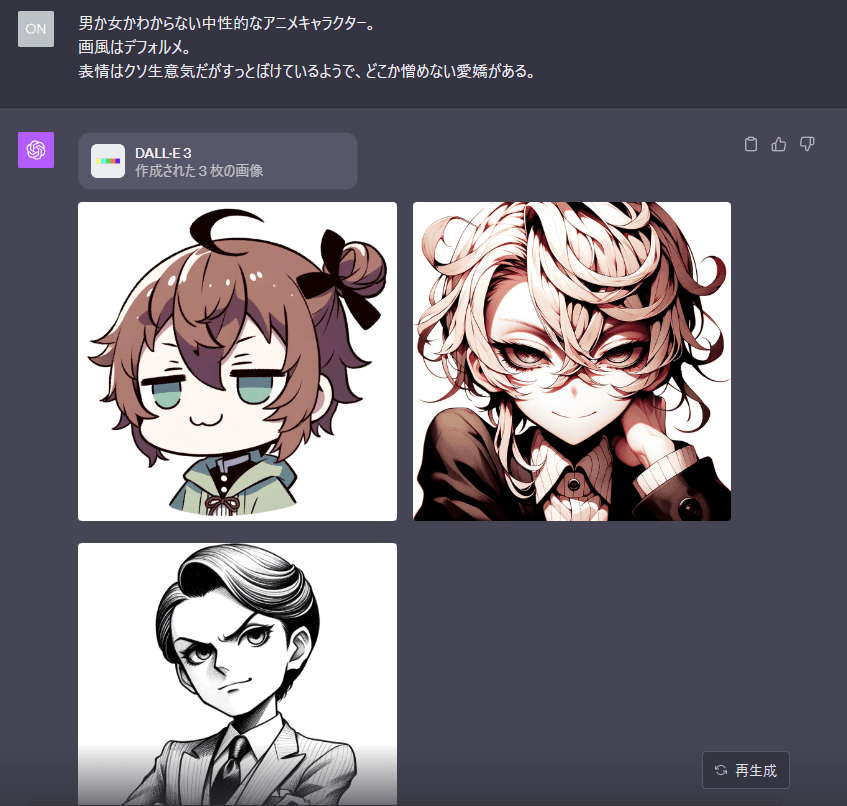
このように、文章から推測される画像を最大4枚出力してくれます。
出力された画像をクリックするとプロンプトが表示されますが
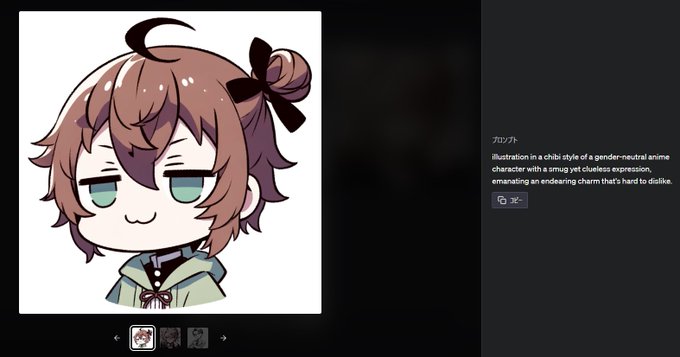
プロンプトをそのまま打ち込んでも全く同じ画像が出力されるわけではないようです。
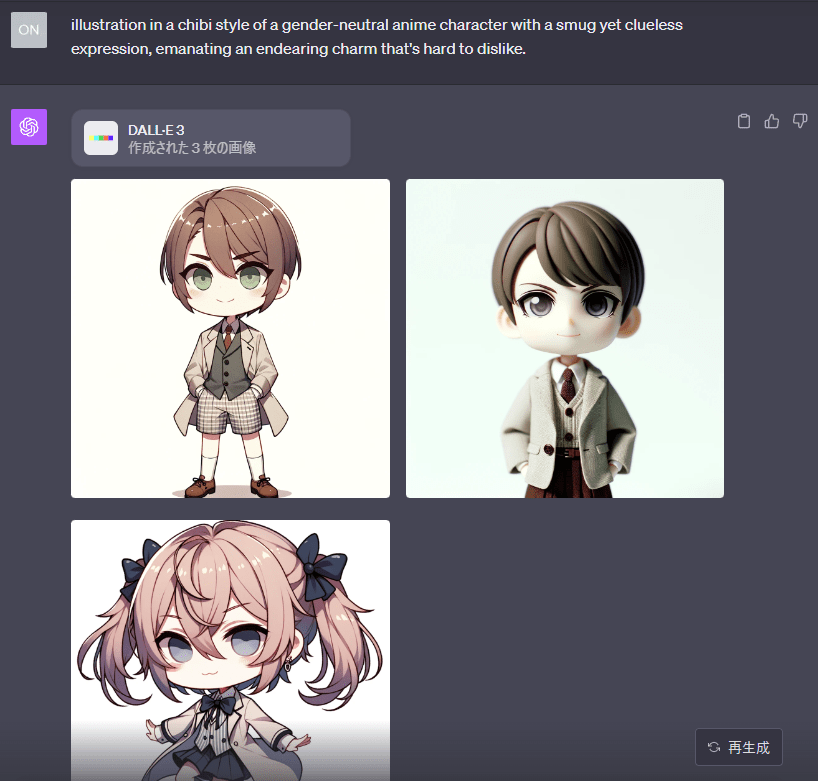
むぅ…微妙に使いづらい。
DALL·E3で生成した画像は商用利用できるか
商用利用可能です。コンテンツポリシーと利用規約はしっかりと確認しておきましょう。
これを見る限りほぼほぼあらゆる用途に使用可能で、生成した画像を印刷したり、画集として販売したり、グッズのイラストとして使ったりすることも可能です。
ただし性的な表現や暴力・グロ表現など年齢制限がかかるようなものはそもそも OpenAI のセーフガードに弾かれます。
DALL·E3でできること/できないこと
ということで早速DALL·E3を使って色々試してみましょう。
DALL·E3でできること/できないこと、できることの度合いや方向性などを探ってみます。
オリジナルキャラクターの別パターン画像を作成

まずはこのサイト「電脳世界」のマスコットキャラクターでもある「星海せかい」ちゃんの別パターン画像を作れるか試してみましょう。
別パターンを作る前に、元の画像の特徴を正確に再現できるかどうか試してみます。
まずはChatGPT(GPT-4)で画像を再現するためのプロンプトを出力させます。

で、出てきたプロンプトをDALL·E3に入力。
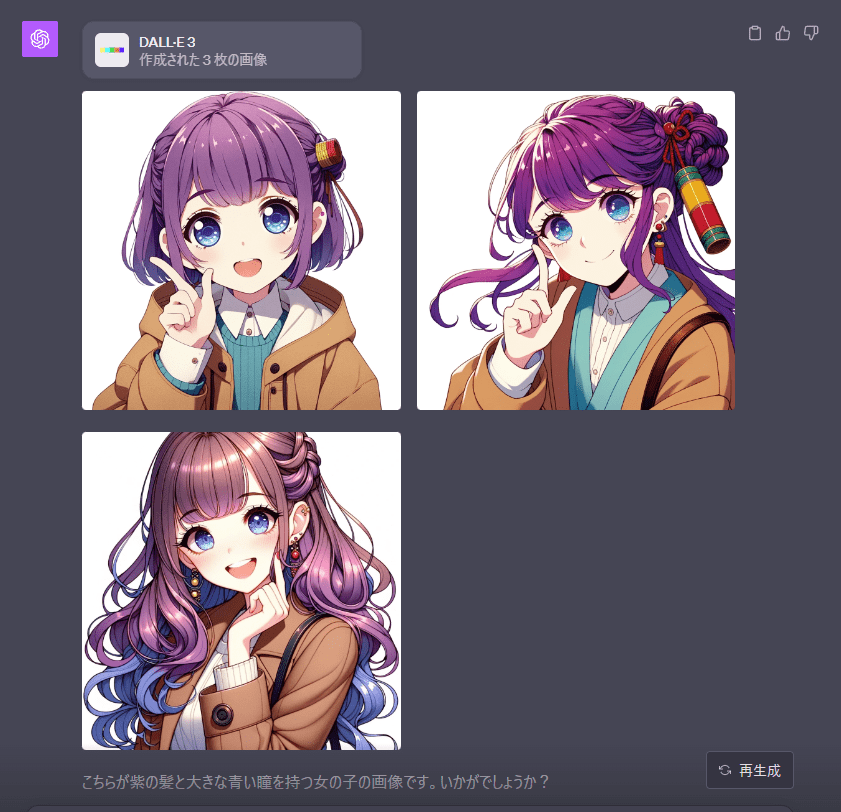
うむ、全く別人ですね。
一応髪の色や服装、ポーズなど、大きな枠で考えれば特徴は似ているのですが、同じキャラクターには見えません。
同じキャラクターを出力できない以上、別バージョンを作る…というのは難しそうです。
Webアプリの構成図(アーキテクチャ)
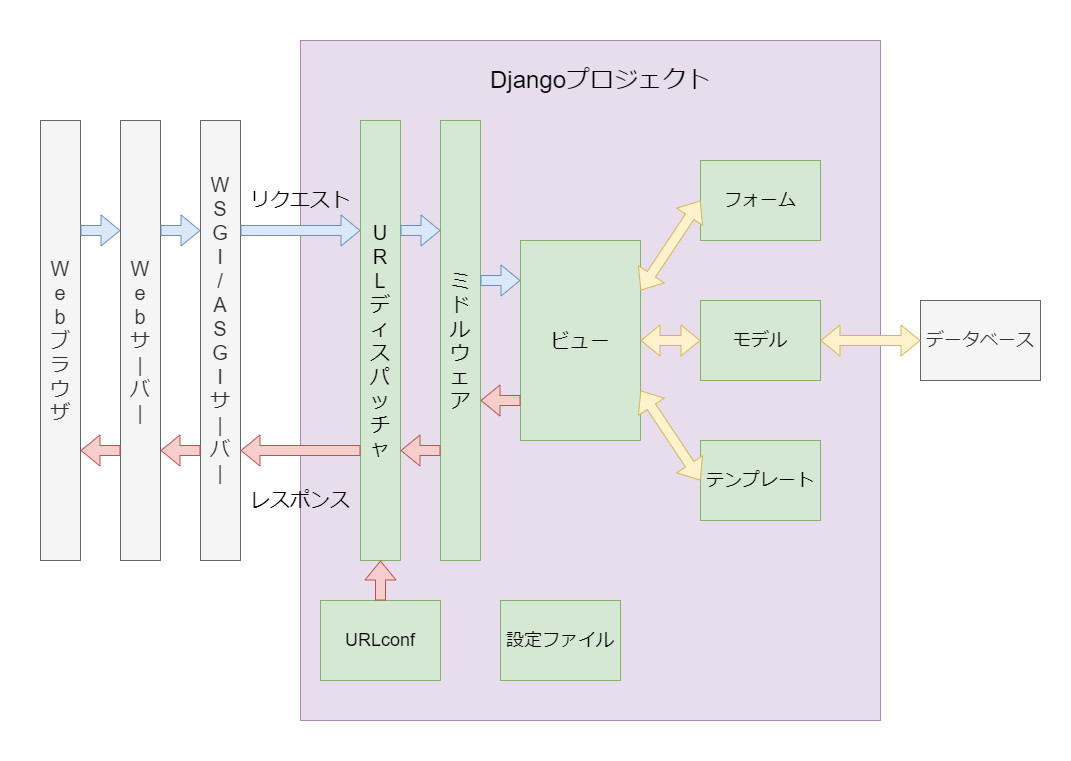
こういうのですね。これがDALL·E3で出力可能かどうか、試してみましょう。
なるほど、これじゃないんだよなぁ。
イラストとしては全然使えそうですが、図面などを作るのはムリそう。
本の表紙
これはまぁいけそうなのはなんとなくわかりますが、どの程度方向性が一致するかというのと、クオリティの確認のため試してみます。
なるほど全然良さそう。
あとはこれをベースに画像編集ツールでタイトルなど文字を入れれば商用レベルにも使えそうですね。
ただし表紙絵として使うならサイズの指定は必須。確認しておきましょう。
おや、指定したサイズと違う。これはちょっと使いづらいな…。
他作品のパロディや実在する商品の入った画像
著作物に関してはOpenAIのセーフガードでかなり厳しく守られているらしく、漫画のタイトルを出さず、登場人物名も出さず、技名を出しただけでもガードされました。
また、商標権についてもガチガチに守っているらしく、お菓子の画像を出力することもできませんでした。
実在の人物の似顔絵
有名人の似顔絵が出力できるかどうかテストしてみましたがダメでした。
ただし故人であれば可能な様子。
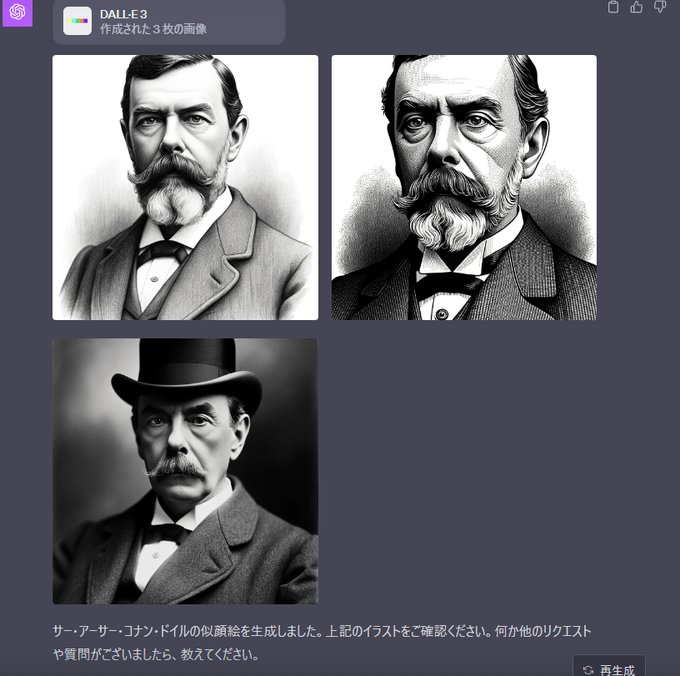
歴史上の人物の似顔絵はいけそうですね。
まとめ
ここまで試した限りパッと思い当たる用途は、イラスト、アート、ロゴ、本の表紙、絵本や小説の挿絵あたりでしょうか。
逆に、キャラクターグッズやゲームのキャラクターなど、同一のキャラクターに見えなければならないものはこのままだと難しそうです。
「文章で指示を出せる」という点は画期的ではありますが、今のところ他の画像生成AIではできなかった用途に使える…というところまでは行ってないように思えます。
もちろん他のツールを組み合わせたり、工夫次第でできることは広がりそうですが、あまり手間がかかるようだとツールが追い付いてくる方が早いかもしれませんね。