この記事ではリストと並び複数のデータを扱うためによく使われるデータ構造の1つである辞書について学びましょう。他のプログラミング言語では「連想配列」や「連想記憶」と呼ばれることもあります。
目次
辞書とは
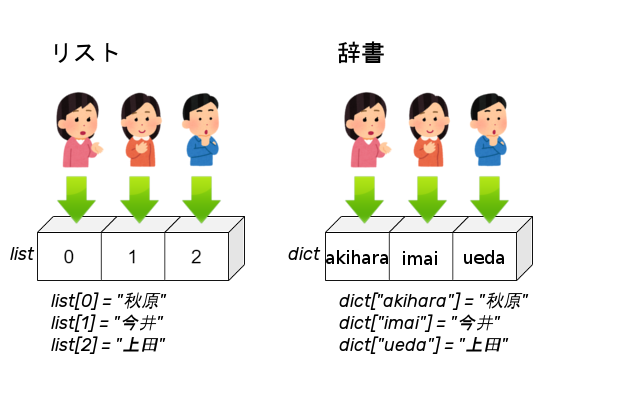
リストではインデックス番号で要素を指定することができましたが、辞書はキーと呼ばれる文字列でデータを指定します。
もちろんリストのように要素を追加したり、上書きしたり、削除することも可能です。
辞書の要素はキーで管理することができるため、データベースやAPIとやり取りするデータの処理によく使われます。
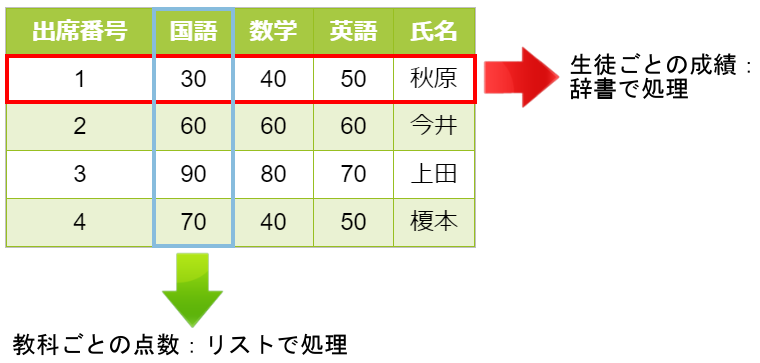
例えば上のような表データがあった時、各教科の先生が生徒の得点を出席番号順に知りたい時はリストが便利ですが、クラス担任の先生が生徒の名前からその生徒の成績を知りたい場合には辞書が便利です。
この場合は秋原くん用の辞書の中で次のようにキーと値が対応しています。
| キー | 値 |
|---|---|
| 出席番号 | 1 |
| 氏名 | 秋原 |
| 国語 | 30 |
| 数学 | 40 |
| 英語 | 50 |
辞書の作成
辞書を作成するには次のように辞書全体を波括弧で囲んで、各要素をカンマで区切り、その中にキーと要素の値をコロンで区切って記述します。
辞書名 = {キー1:要素1, キー2:要素2, キー3:要素3}
例えば先ほどの成績表であれば次のように記述します。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
print(akihara)
実際に実行してみましょう。
{'出席番号': 1, '氏名': '秋原', '国語': 30, '数学': 40, '英語': 50}
辞書はこのように波括弧で囲まれて表示されます。
要素の取り出し
辞書の要素を個別に取り出す方法についてみていきましょう。
リストがインデックス番号で要素を指定するのに対し、辞書ではキーを使って要素を指定します。
辞書名[キー]
例えば先ほど作成した辞書から英語の点数を取り出したい場合は次のように記述します。
print(akihara["英語"])
辞書のキーは次のように変数で指定することもできます。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
eng = "英語"
print(akihara[eng])
辞書でもリストと同じく、要素の個数を確認するにはlen関数を使います。
例えば先ほどの辞書の要素個数を表示するには次のように記述します。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
print(len(akihara))
辞書の基本操作
次は作成した辞書に要素を追加したり、上書き、削除する方法についてみていきましょう。
要素の追加
辞書に要素を追加するには次のように辞書名とキーを指定して値を代入します。
辞書名[キー] = 値
実際に先ほどの辞書にデータを追加してみましょう。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
akihara["理科"] = 60
print(akihara)
実行結果は次のようになります。
{'出席番号': 1, '氏名': '秋原', '国語': 30, '数学': 40, '英語': 50, '理科': 60}
「理科」というキーで「60」という値が追加されているのがわかります。
要素の上書き
辞書の要素を上書きするには要素の追加と同様、辞書名とキーを指定して値を代入します。
試しに先ほどのコードの「数学」の値を「70」に上書きしてみましょう。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
akihara["数学"] = 70
print(akihara)
実行結果は次のようになります。
{'出席番号': 1, '氏名': '秋原', '国語': 30, '数学': 70, '英語': 50}
要素の削除
辞書の要素を削除するにはdel文を使います。
では例として先ほどの辞書から「国語」を削除してみましょう。
akihara = {"出席番号":1, "氏名":"秋原", "国語":30, "数学":40, "英語":50}
del akihara["国語"]
print(akihara)
実行結果は次のとおりです。
{'出席番号': 1, '氏名': '秋原', '数学': 40, '英語': 50}
辞書から「国語」のキーとそれに対応する「30」という値が削除されているのがわかります。
ちなみにdel文は辞書だけでなく、リストの要素やオブジェクトを削除することもできます。
辞書のソート
辞書もリストと同じようにあいうえお順や数字順に並べ替えることができますが、リストとは少し異なる部分があります。
実際に例を見ながら進めていきましょう。次の辞書は学校の生徒名とテストの点数をまとめた辞書です。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
ではこの辞書をリストと同じようにsorted関数で並べ替えて出力するとどうなるでしょうか。実際に試してみましょう。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
print(sorted(scores))
実行結果は次のとおりです。
['アキハラ', 'イマイ', 'ウエダ']
このように、辞書をsorted関数を使って出力すると、辞書のキーがあいうえお順に並べ替えられたリストとして出力されます。
リストの章でも説明しましたが、sorted関数は要素を並べ替えたリストを返すだけで、元の辞書そのものが並べ替えられるわけではありません。
辞書のキーを並べ替えたリストを作りたい場合は新しくリストを作って並べ替えたデータを代入します。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
new_list = sorted(scores)
print(scores)
print(new_list)
実行結果は次のとおりです。
{'イマイ': 30, 'ウエダ': 65, 'アキハラ': 40}
['アキハラ', 'イマイ', 'ウエダ']
元の辞書はそのままで、新しく作ったリストに辞書のキーを並べ替えたリストが代入されているのがわかります。
さて、辞書のキーをソートして表示することはできましたが、キーだけでなく値も含めて並べ替えたい時はどうすれば良いのでしょうか。
この場合は辞書そのものをsorted関数に渡すのではなく、辞書をitemsメソッドで呼び出したものをsorted関数に渡します。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
print(sorted(scores.items()))
実行結果は次のとおりです。
[('アキハラ', 40), ('イマイ', 30), ('ウエダ', 65)]
ちゃんとキーと値がキーのあいうえお順でソートされて表示されました。
ですがよく見ると辞書を出力したときとは表示が違います。これはitemsメソッドによって辞書のキーと値が1組のペアとなったタプルというデータ構造に変換され、そのリストとして出力されているためです。
タプルはリストと同じように複数のデータを扱うためのデータ構造の1種ですが、内容の変更ができないためプログラム中で変わってほしくないデータを取りまわすのによく使われます。
辞書をループで処理
辞書のデータをループで処理する方法についても知っておきましょう。
for文で辞書の中の値を全て取り出すには次のように記述します。
for 変数 in 辞書名: print(辞書名[変数])
このようにfor文の「くり返す範囲」に辞書を指定すると辞書のキーを順番に取り出して変数に代入してくれます。
あとはくり返し処理の中で辞書の値をキーで指定して取り出すよう記述すれば、辞書の値を全て取り出して表示することができます。
実際に先ほどの辞書を使って記述してみましょう。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
for members in scores:
print(scores[members])
実行結果は次のとおりです。
30 65 40
辞書の値が1つずつ順番に出力されています。
辞書のキーと値をペアで取り出すにはitemsメソッドを使い次のように記述します。
for (変数1,変数2) in scores.items(): print(変数1 + 変数2)
このように記述することで変数1にキーが、変数2に値が代入されてループ処理が実行されます。
実際に先ほどの辞書で試してみましょう。せっかくなので文字列を連結してみます。
scores = {"イマイ":30, "ウエダ":65, "アキハラ":40}
for (members,points) in scores.items():
print(members + "君は" + str(points) + "点です")
実行結果は次のとおりです。
イマイ君は30点です ウエダ君は65点です アキハラ君は40点です
ちゃんとキーと値をペアで取り出して文字列として使用することができました。
集合に対して使える比較演算子(in,not in)
リストや辞書、タプルといったデータの集合に対して使える比較演算子についても知っておきましょう。
これらは集合だけでなく、文字列の中に指定した文字が含まれるかどうかを判定することもできます。
in
要素 in 集合
inは集合や文字列の中に指定した要素や文字が含まれるかどうかを判定する演算子です。
例えば次のように記述するとリストに”イマイ”という要素が含まれている時に条件がTrueとなり「イマイくんが含まれています」と表示されます。
members = ["アキハラ", "イマイ", "ウエダ"]
if "イマイ" in members:
print("イマイくんが含まれています")
実際にプログラムを実行すると次のように表示されます。
イマイくんが含まれています
辞書の場合は指定した要素が辞書のキーに含まれるかどうかを判定します。
not in
not in はinの逆で、指定した要素が含まれない場合にTrue、含まれる場合にはFalseとなります。
例えば次のように記述すると”オオニシ”という要素が含まれていない時に条件がTrueとなり、「オオニシくんは含まれていません」と表示されます。
members = ["アキハラ", "イマイ", "ウエダ"]
if "オオニシ" not in members:
print("オオニシくんは含まれていません")
実行結果は次のとおりです。
オオニシくんは含まれていません